
和美大家说 | Elasticsearch之相关性调整实践
前言:
信息检索的核心问题就是在文档集中为用户检索最相关的子文档集,依靠排序算法对检索结果按照相关性进行排序,排序后的结果作为对用户所提出查询的回应。本文主要介绍搜素引擎Elasticsearch中全文检索相关性调整实战。
相关性算法
Elasticsearch在ES5版本之前默认使用经典的TF/IDF相关性算法,ES5之后默认使用基于概率模型的BM25(Best Match 25)相关性算法。和TF/IDF相比在BM25中词频对相关性评分的影响降低了,当TF无限增加时,BM25算法会趋于一个数值,如下图,ES提供了一种非常好的方式,实现了可插拔式的配置,允许我们控制每个字段的相关性算法。在 Mappings 设置阶段,我们可以调整 similarity 的参数并给不同的字段设置不同的 similarity 来达到调整相关性算法的目的。ES 提供了几种可用的 similarity,本文主要讨论BM25。
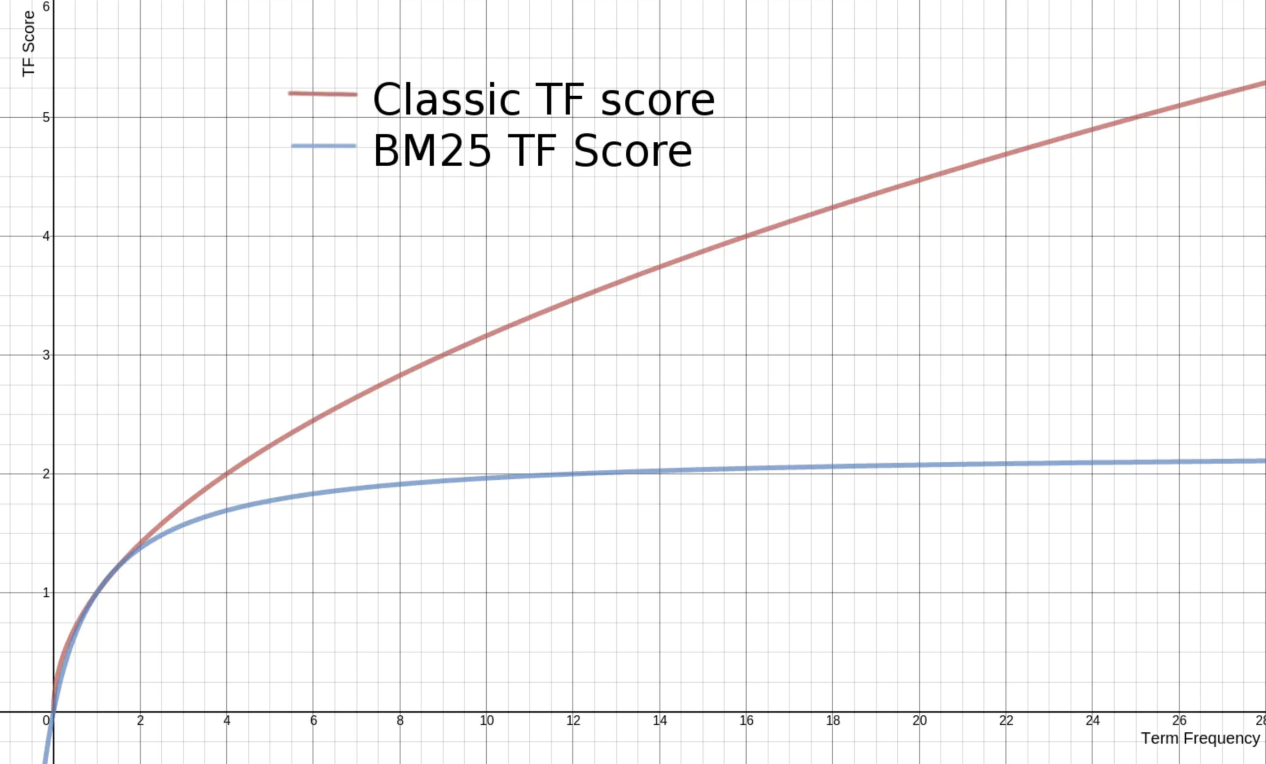
此处放上BM25算法公式,便于接下来对调整相关性实战结果的理解
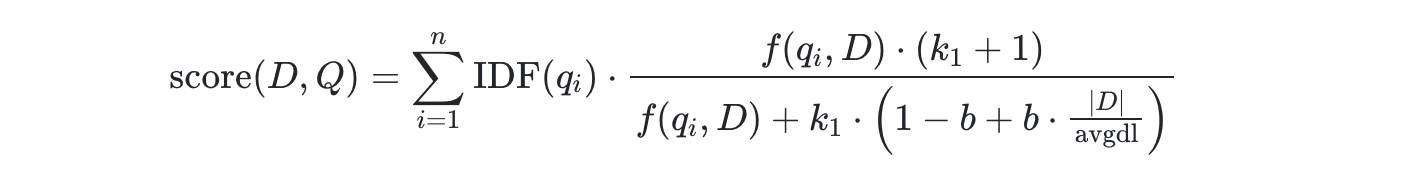
-
· score(D,Q):这个公式最终的结果,Q表示query,D表示doc,表示一个query对一个doc的最终的总得分;
-
· IDF(qi):idf算法对一个term的值;
-
· f(xxx)/xxx:这一大串公式,即tf norm的计算公式;
-
· ∑ 求和符号:idf和tf norm结果相乘,最后求和;
-
· 其中k1 默认值是1.2, 数值越小,饱和度越高,b默认值是0.75(取之范围 0~1),0代表禁用Normalization。
-
BM25公式参见: https://en.wikipedia.org/wiki/Okapi_BM25
-
调整相关性
虽然使用 ES 可以非常方便快速地搭建出搜索平台,但搜出来的结果往往不符合预期。因为 ES 是一个通用的全文搜索引擎,它无法理解被搜索的内容,通用的配置也无法适合所有内容的搜索。所以 ES 在搜索中的应用需要针对具体的平台做很多的优化才可以达到良好的效果。
ES 搜索结果排序是通过 query 关键字与文档内容计算相关性评分来实现的。想掌握相关性评分并不容易。首先 ES 对中文并不是很友好,需要安装插件与做一些预处理,其次影响相关性评分的因素比较多,这些因素可控性高,灵活性高。
本文示例索引数据示一份图片的描述文档数据,如下图:

1. 调整相关性之前应该首先确保文档质量及分词的合理性
2. 优化 ES Query DSL 调整相关性
最初使用multi_match来查询
示例:

这样使用非常方便和快速,并且实现了全文搜索的需求。但是搜索的结果可能不太符合预期,接下来我们增加类别和时间的筛选条件,目的是筛选出同类别及较新的数据。
使用 bool 查询的 filter 增加筛选
在应用中,我们应该避免直接让用户针对所有内容进行查询,这样会返回大量的命中结果,如果结果的排序稍微有一点出入,用户将无法获取到更精准的内容。
针对这种情况,我们可以给内容增加一些标签、分类等筛选项提供给用户做选择,以达到更好的结果排名。这样搜索时被 ES 引擎评分的目标结果将会变少,评分的抖动影响会更小。
实现这个功能就使用到 bool 查询的过滤器。bool 查询中提供了4个语句,must / filter / should / must_not ,其中 filter / must_not 属于过滤器,must / should 属于查询器。关于过滤器,你需要知道以下两点:
·过滤器并不计算相关性评分,因为被过滤掉的内容不会影响返回内容的排序;
·过滤器可以使用 ES 内部的缓存,所以过滤器可以提高查询速度。
这里需要注意:虽然 must 查询像是一种正向过滤器,但是它所查询的结果将会返回并会和其他的查询一起计算相关性评分,因此无法使用缓存,与过滤器并不一样。
一般一个文档拥有多个可以被筛选的属性,例如 id、时间、标签、分类等。为了搜索的质量我们应该认真地对文档进行打标签和分类处理,因为一旦选择了过滤,即使用户的搜索关键词再匹配文档也不会被返回了。
示例:

至此搜索的时候经常会出现搜索结果和搜索关键词不是连续匹配的情况,让和搜索语句顺行一致的数据排序更靠前,该怎么做呢?继续往下看:
使用 match_phrase 提高搜索短语的权重
ES 专门记录了词语的位置信息用于查询,在DSL中是使用match_phrase 查询。match_phrase 要求必须命中所有分词,并且返回的文档命中的词也要按照查询短语的顺序,词的间距可以使用 slop 设置。
match_phrase 虽然帮我们解决了顺序的问题,但是它要求比较苛刻,需要命中所有分词。如果单独使用它来进行搜索,会发现搜索出来的结果相比 match 会大大减少,这是因为匹配若干个词的文档和匹配顺序不对的文档都没被返回。
这时候可以采用 bool 查询的 should 语句,同时使用 match 与 match_phrase 查询语句,这样相当于 match_pharse 提高了搜索短语顺序的权重,使得能够顺序匹配到的文档相关性评分更高。
示例:

使用 boost 调整查询语句的权重
上文中所有字段都无权重之分。根据常识我们知道,caption的权重应该高于其他字段,显然不能和其他字段是一样的得分。
查询时可以用 boost 配置来增加权重,不过这里设置的对象并不是某个字段,而是查询语句。设置后,查询语句的得分等于默认得分乘以 boost。
设置 boost 有几个需要注意的地方:
-
·数据质量高的字段可以相应提高权重;
-
·match_phrase 语句的权重应该高于相应字段 match 查询的权重,因为文档中按顺序匹配的短语可能数量不会太多,但是查询关键词被分词后的词语将会很多,match的得分将会比较高,则 match 的得分将会冲淡 match_phrase 的影响;
-
·在 mappings 设置中,可以针对字段设置权重,查询时不用再针对字段使用 boost 设置,但不建议在索引时期设置boost,不便于后期调整boost值。
示例:

使用 function_score 增加更多的评分因素
影响文档评分的还有一些因素,例如我可能会经常考虑以下问题:
-
·时间越近的文档信息比较及时,对用户更有用,应该排在前面;
-
·平台中热门的文档,可能用户比较喜欢,应该比其他文档好;
-
·文档质量比较高的,更希望让用户看到,那些缺失标签与摘要的文档并不希望用户总是看到
-
·运营人员有时候想让用户搜到正在推广的文档;
-
·……
我们可以通过增加更多的影响报告评分的因素来实现以上场景,这些因素包括:时间、热度、质量评分、运营权重等。
function_score 支持用户自定义相关性评分计算公式,也提供了多种类型方便我们快速应用。function_score 提供了五种类型:
-
·script_score,这是最灵活的方式,可以自定义算法;
-
·weight,乘以一个权重数值;
-
·random_score,随机分数;
-
·field_value_factor,使用某个字段来影响总分数;
-
·decay fucntion,包括gauss、exp、linear三种衰减函数。
此处以script_socre为例,比如将业务定义的rank_socre 值作为相关性分值计算的一个因素,以增强业务中需要提高提高排序的的文档。
示例:
其他类型请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
3. 相关性算法优化
上文主要介绍了ES静态相关性评分调整的实践示例,下文我们再来讨论一下动态评分的计算。
所谓动态评分,就是用户每次查询都要计算用户查询关键词与文档的相关性,更细一点来说,就是实时计算全文搜索字段的相关性,即对ES默认BM25算法参数的调整。通过上文中BM25相关性算法的简单说明可知,有两个参数可供我们调整。
-
·k1 词频归一化控制参数;
-
·b 文档长度影响因子;
-
·在优化 BM25 的 k1 和 b 时,我们要根据搜索内容的特点入手,仔细分析检索的需求。
例如在示例的索引数据中 content 字段的质量参差不齐,甚至有些文档可能会缺失此字段,但此文档对应的真实数据(可能是某文件、某视频等)质量很高,因此放入 ES 中 content 字段的长度并不能反映文档真实的情况,更不希望 content 短的文档被突出,所以我们要弱化文档长度对评分的影响。
根据 k1 和 b 的描述,我们将 BM25 模型中的 b 值从默认的 0.75 降低,具体降低到多少才合适,还需要进一步的尝试。这里我以调整到 0.2 为例。
示例:
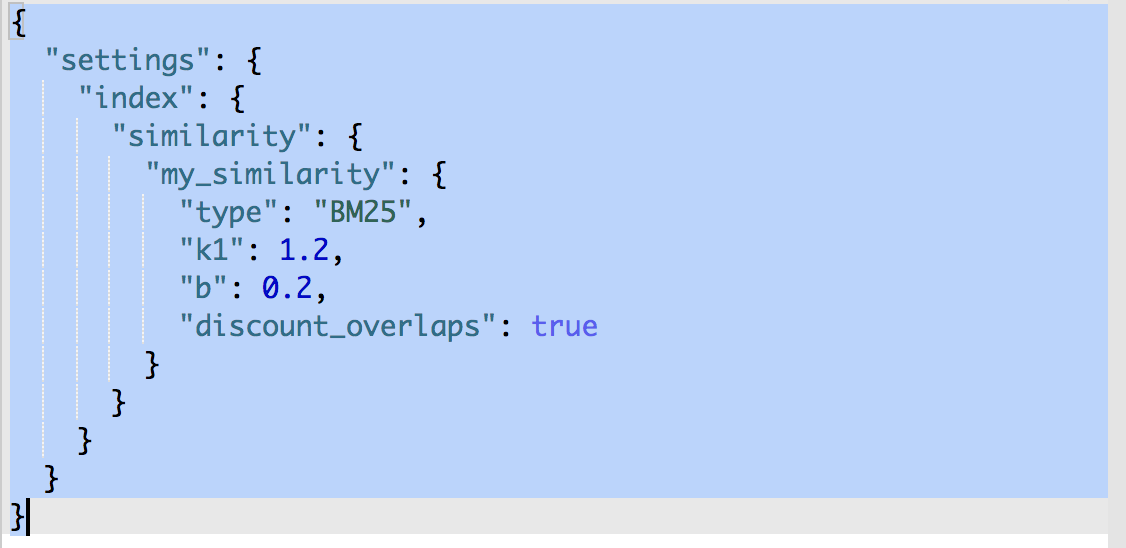
k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证, 在索引数据和Query DSL没调整优化到无能为力时,建议不要轻易去优化相关性算法。
结 语
本文相关性调整实践主要为了说明ES相关性优化思路,希望对读者有所帮助,更多高级优化参数及方式请参考官方文档。相关性优化是一场持久战,坚持每天分析几个bad case,找到原因,才好下手优化。
-
-

