
和美大家说 | 细粒度命名实体识别分类
命名实体识别是自然语言处理任务中基本但是关键的任务,细粒度实体识别因为其种类过多,分类标准不一致的问题,即使目前各种大型预训练模型的出现,细粒度实体识别任务仍然还在探索之中。根据一些下游任务的需求,命名实体识别任务也延伸到细粒度的实体分类(Fine-Grained Entity Typing,下文简称FET)。本文将主要介绍两篇关于现有的针对细粒度实体分类的方法。
在细粒度实体分类中,一般会使用mention来表示在文本中实体的指代,FET任务是已知实体的边界以及上下文,来预测实体的类别,现阶段公开的数据集主要以下三类:FIGER /BBN / OnToNotes。细粒度实体分类需要根据上下文给mention一个或者多个标签。细粒度命名实体分类是指在普遍的人名、组织、地点的粗粒度后,更加细致的分类,并且同一个实体中,在不同的上下文中具有不同的含义,比如如下几句话:
1、 美国第44届总统是奥巴马;奥巴马实体在该句的实体类别应该是:人物 / 政治家
2、奥巴马是一个xx书的作者;奥巴马实体在该句的实体类别应该是: 人物 / 作者
3、奥巴马出生于1961年4月的马耳他;奥巴马实体在该句的实体类别应该是: 人物 /
1、Hierarchical Entity Typing via Multi-level Learning to Rank[1]
在这篇文章中,对实体的表示方式利用了树的层次结构,只有当父节点的实体类型是有效的,下层的实体结构才会是有效的,如下图所示。
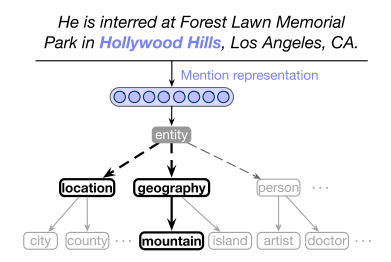
论文采取了树的形式表示,用"/" 表示第零级,再以此往下/person/author, /location/city等。针对公开的三类细粒度实体分类数据集的表示如下:

论文对于标签的标注引入了两个概念:exclusive和undefined。exclusive是指类别x属于类别,但是x不是y中任何一个现有子类,在处理数据时加入了一个other的类别,如同上图所示的AIDA数据;undefined是指x属于类别y,但是否是y的子类是未知,这个方法则不需要改变样本中的数据集标签。
在对mention的表示上,经过作者的尝试,采用了ELMO的方式而非BERT的编码方法,猜测可能的原因是ELMO这种低嵌入的方式就能很好的表征FET任务了,可以充分利用到字符级嵌入信息,BERT可能更适合高级语义特征任务,比如如阅读理解。
论文用不同的词嵌入基于注意力权重的加权平均,对mention的表征通过ELMO获得每个词的词向量,这里也会对ELMO实施一个dropout,再乘以上一个权重后做MaxPooling(最大池化)得mention的表示m,再通过m作为Query,对输入的句子做注意力,得到每个词的注意力权重,在用它与上下文的动态词向量做加权求和得到上下文表征c,最后再将m与c接在一起的到[m;c]作为下游分类解码器的输入。具体的公式表达如如下所示:
![]()

在得到相应的输入特征表示后,解码器接受上述处理的特征喂入一个两层的前馈网络,将mention-context嵌入到与输出类型一致的特征空间。同时,该篇文章提出了先计算每个类别的hinge loss并且将正样本排在负样本前面。同时,论文通过排序模型在不同的层级上制定了不同的margin,计算损失时考虑到了不同层次之间的关系,其中lev(y)表示输出的类型的层级。文章指出正样例的得分应高于父节点;父节点得分应高于任何子节点负样本的得分,同级的正样本得分也高于该级负样本的得分,则具体的loss function 如下:
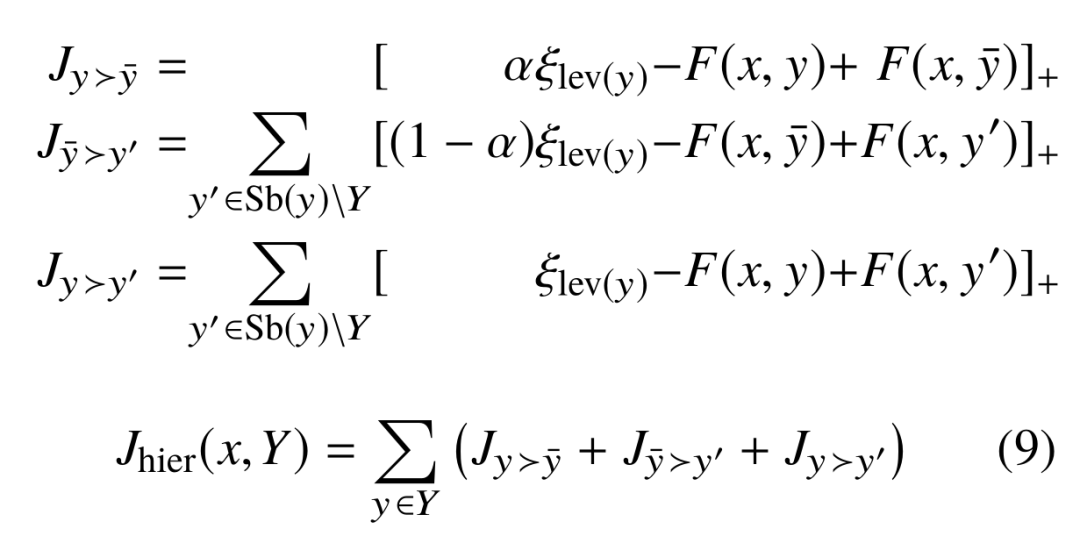
最终实验结果采用了ELMO所有层的结果,实验结果表现如下:

消融实验表明,除去之前AIDA数据的相关的baseline,虽然指标方面仍然达不到粗粒度实体识别任务的表现,但是加入层次化的排序学习或类型关系约束在FET任务的不同数据集上有着4%-8%的提升。
2. Zero-Shot Open Entity Typing as Type-Compatible Grounding[3]
该篇文章提出在最小限度的监督,不借助额外数据的情况下同时利用实体指称的语义表示和实体类型的结构感知表示实现FET任务,将细粒度实体分类建模为一个匹配问题,通过检索加规则匹配的方法去处理零样本实体分类问题。
文章假设一个实体在维基百科中一定对应着相应的实体类型,鉴于在维基百科也存在没有包括了所有实体类型的情况,如果不存在则会给出在数据中接近的实体类型,主要表示如下:

论文中,输入是句子以及句子中mention表示,和该mention对应的类别,输出一个类型的元组。论文采用了Gabrilovich和Markovitch在2007年提出的ESA方法[2]来表示语料每个字向量,根据维基的内容,生成在wikilinks语料中的对应的单词语义表示,同时,再通过ELMO获取输入句子和相应的mention的向量,采用预训练的ELMo向量直接编码提及所在上下文,ELMo句向量的编码被应用于句子相似度的计算。其得分表示公式如下:

该公式可以表示为如下图所示:
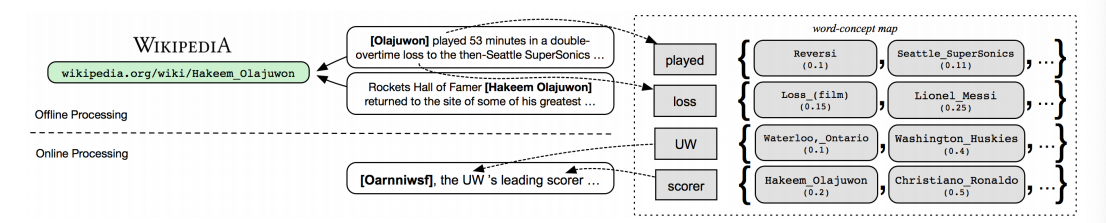
在对类型进行推理的阶段,文章中指出会先选择一个最相似或者最接近的粗粒度的实体类型,再在粗粒度的相应的类别下选择合适的细粒度类别。
粗粒度选择的公式:

细粒度类别选择的公式:
![]()
这里tc则是上述步骤中选择好的粗粒度实体类型。
最终的实验结果如下表所示:

实现结果表明,该方法也优化了ZOE方法在FET任务在细粒度实体分类各个开源数据表现。
随着各种大型预训练的模型进入我们的视线,粗粒度的命名实体识别任务的表现得到来很大的提升,一个有效的细粒度实体分类在实际的工程应用中也能发挥不少作用,但是现有的研究在这方面还有较长的一段路要走,并且对于更加细致的实体分类,数据质量更加取决于标注员如何理解互斥和未定义这两种类别,未来也是一个值得探索的方向。
Reference:
[1]Chen, Tongfei. Chen, Yunmo. Van Durme, Benjamin. 2020. Hierarchical Entity Typing via Multi-level Learning to Rank
[2]https://blog.csdn.net/c9yv2cf9i06k2a9e/article/details/106726062
[3]Evgeniy Gabrilovich and Shaul Markovitch. 2007. Computing semantic relatedness using wikipediabased explicit semantic analysis. In IJcAI, volume 7, pages 1606–1611.
[4]Zhou B, Khashabi D, Tsai C-T, et al. Zero-Shot Open Entity Typing as Type-Compatible Grounding[C]. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018: 2065-2076.
[5] https://zhuanlan.zhihu.com/p/107488988

